





Introduction:
In the ever-evolving landscape of software development, scalability remains a foundation for the success of applications, both big and small. This is where the concept of the Scale Cube comes into play, offering a multidimensional approach to scaling that goes beyond the traditional “make it bigger” strategy.
What is the Scale Cube?
The Scale Cube is a conceptual model that represents the three dimensions of scaling services: the X-Axis, the Y-Axis, and the Z-Axis. This model is not just a theoretical construct, but a practical tool that helps teams to understand and implement effective scaling strategies.
In the domain of service scaling, it's easy to default to the simple approach of adding more resources, a strategy commonly referred to as horizontal scaling. However, the Scale Cube encourages teams to think beyond just horizontal scaling.
It introduces the idea of architectural design as a crucial element in promoting scalability. By considering architectural design, teams can ensure that their services are not just scaled up in terms of resources, but are also designed and structured in a way that maximizes their ability to handle increased demand.

the X-Axis (Cloning)
It’s the most intuitive & simplest approach for scaling monolithic applications. It involves cloning N instances of an application running behind a load balancer to distribute the workload such that each instance can handle 1/N of the workload.
One example is using NGINX as a load balancer to efficiently distribute the traffic across the cloned instances
Drawbacks of this approach is:
Caching will require more memory.
Cloning the entire instance will potentially require more computational resources which may not be used efficiently if the load is uneven and can lead to inefficiencies because not all parts of the application may need to scale at the same rate or in the same way.
Lack of complexity reduction in the application’s codebase.
Database performance and bandwidth becoming a bottleneck.
The Y-Axis (Decomposition of services/ functionality)
Decomposing involves breaking down the application as different standalone components/ features/ use cases or “microservices” to allow you to scale these microservices efficiently and independently as some features can be more resource intensive than the others. The Y-Axis is the most scaling dimension with the most repercussions.
There are a couple of different ways of decomposing the application into services. One approach is to use verb-based decomposition and create services that implement a single use case such as “checkout”, “payment”.
The other option is to decompose the application by noun and create services responsible for all operations related to a particular entity such as “employee management”. Applications might use a combination of verb-based and noun-based decomposition.
Drawbacks of this approach is:
Deploying multiple microservices can increase the operational complexity as each service may have its own dependencies, database, and configuration requiring advanced orchestration and monitoring tools.
When data is distributed across multiple services, maintaining consistency becomes challenging, and a solution to that is implementing transactions that span multiple services which will require careful design to avoid duplication or inconsistency.
Communication overhead happens when SYNCHRONOUS services attempt to communicate with each other so service-1 has to wait for the response of service-2 which makes them tightly coupled, and introduces network latency. (Note: this is unlike ASYNCHRONOUS services which introduce solutions to reduce the tight coupling problems by using asynchronous protocols like message queues and event streams). ASYNCHRONOUS protocols also have their own drawbacks like (Complexity in handling data, Difficulty in monitoring and debugging, message brokers overhead). Each of these protocols have their own specific use cases. People often use a hybrid approach.
The Z-Axis (Splitting Data by Partition)
It’s similar to the X-Axis scaling in a way that involves running multiple instances of the same codebase, However the key difference is that the application is split in a way such that each instance is responsible only for a certain partition of the whole data. This technique is often used in databases also known as Data Partitioning which consists of Horizontal/ Vertical Partitioning.
Horizontal Partitioning:
Horizontal partitioning divides a table's rows across multiple database tables of the same structure, each holding a portion of the data. This is also referred to as sharding. The goal is to distribute the dataset across multiple servers or partitions to improve manageability, performance, and scalability.
Examples of horizontal partitioning in databases:
List partitioning: partition users in a database based on their country, rows are directed to the appropriate partition based on the country column value
Range partitioning: Partition historical transaction data, like partitioning transactions by date, with separate partitions for different time periods (eg., months, years)
Hash partitioning: Its functionality is similar to the functionality of hash maps in any programming language, It distributes the data across partitions based on the hashed value of the partitioning key (eg., UserID)
2. Vertical Partitioning
Vertical partitioning, on the other hand, divides a table into smaller tables, each containing a subset of the columns. Instead of splitting rows, vertical partitioning splits the columns of a table, which can help improve performance by reducing the amount of data that needs to be loaded from disk for queries that access only a subset of the columns.
Vertical Partitioning Example: If you have a user table with columns for user ID, name, email, and several columns related to user preferences, you might vertically partition this into one table for user identity (ID, name, email) and one or more tables for user preferences. This approach can improve query performance for operations that only need to access identity information.
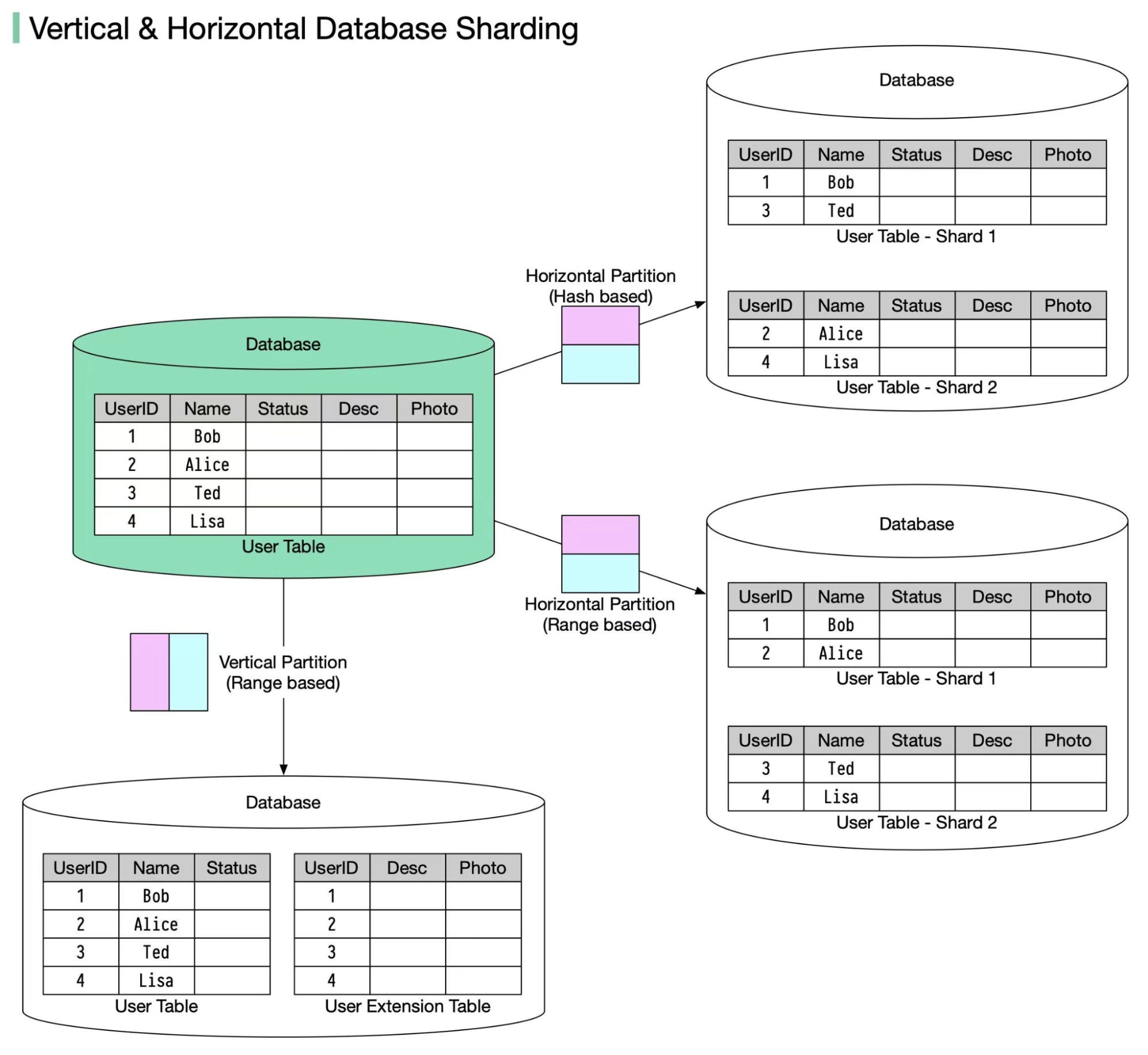
Note that Data Partitioning is obviously handled at the Storage Level of the database.
Also note that before considering scaling on the Z-Axis, the X, Y-Axis approaches should be exploited first as it comes with its own nightmares.
Drawbacks of this approach:
Queries that require aggregation and joins across partitions will definitely become more complex and less performant.
Global searching across the whole database will become very challenging in a partitioned architecture, as it will require querying all the partitions and then aggregating them.
It does not tackle the problem of reducing the application’s complexity
Employing a combination of the 3 axes is often the most effective approach to scale huge systems.
References & Further Reading:
The Art of Scalability: amazon.com/Art-Scalability-Architecture-Org..
Stephen Grider’s Microservices Course:udemy.com/course/microservices-with-node-js..
Designing Data-Intensive Applications:oreilly.com/library/view/designing-data-int..
Vertical Partitioning vs Horizontal Partitioningblog.bytebytego.com/p/vertical-partitioning..